
A few years ago, I worked for a client, and they had a big business problem.
They had 3-5 million paper documents being stored away every single year in a big warehouse, these documents were sensitive and classified.
Now, you can imagine when someone needs to review a document dated at a certain time. An officer would have to go to the warehouse and try to locate this document.
This would become very difficult to find, typically taking 3-4 weeks to locate and send to the requestor.
Here is a perfect scenario for automation and designing a digital document storage solution. So, I was tasked with creating a technical architecture and building it with AWS.
What I loved about this project was that I could design and solve the problem how I saw fit, use the technologies I wanted, and build a lasting solution.
I had a blank cheque to design, build, deliver, and lead a multi-million dollar project.
So the pain points were inefficient and insecure manual processes for scanning, storing and retrieving over 3.5 million sensitive documents in a physical storage centre
I designed a cutting-edge solution using Amazon Web Services (AWS) that digitized the entire document management process to address this.
We developed a custom portal that allowed users to securely scan, upload, and quickly retrieve documents from the cloud while integrating advanced security features like encryption and access controls.
Here is a more simplified view of the solution. The key components are:
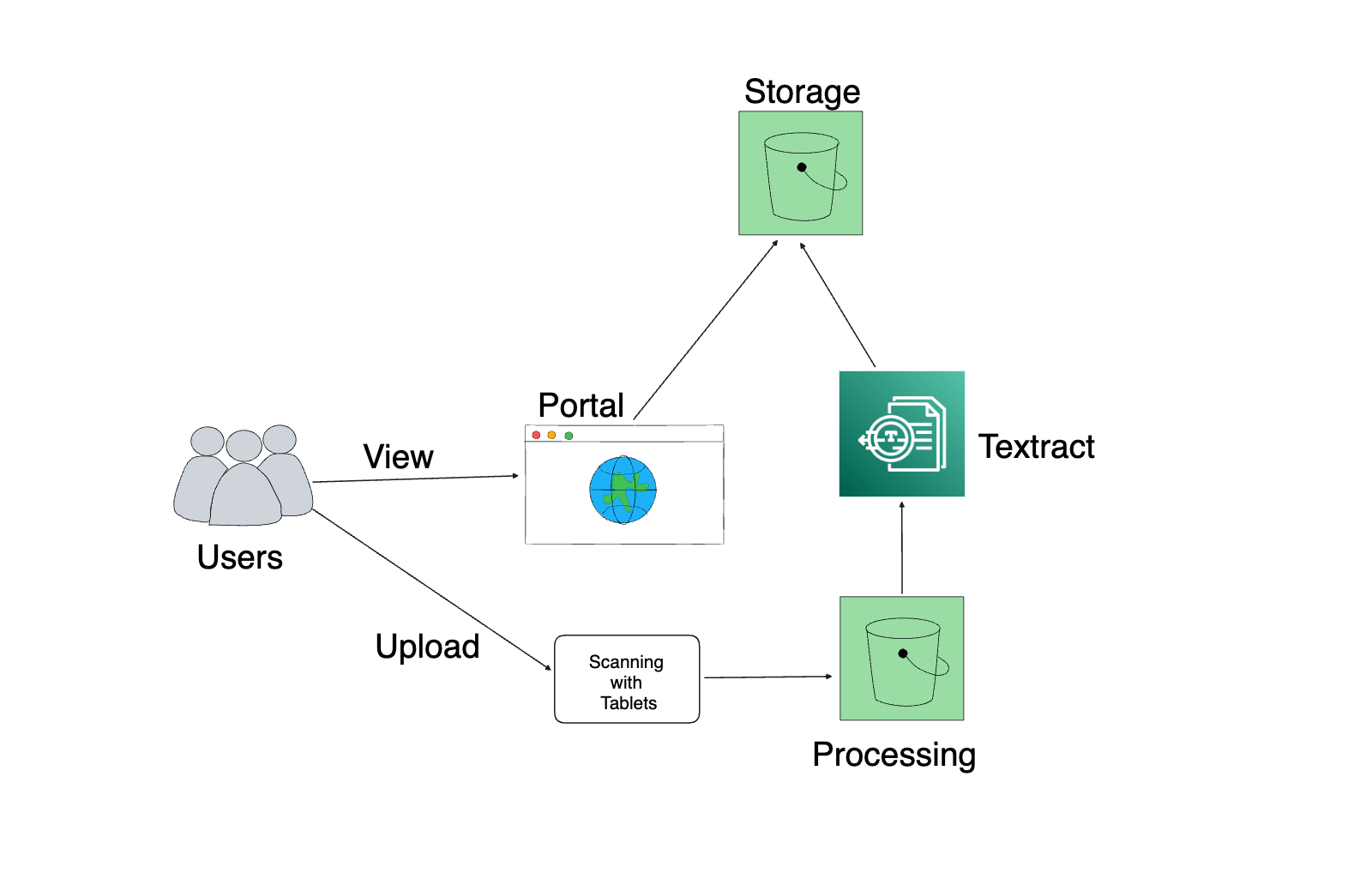
Users: They interact with the portal to view, upload, and retrieve documents.
Portal: A custom web application that provides a user interface for document management.
Scanning with Tablets: Documents are digitized using tablets for uploading to the system.
Textract: AWS Textract is used to extract a unique identifying number from each scanned document, which is used for saving and searching documents from the portal.
Processing: The extracted data from Textract is processed and prepared for storage.
Storage: AWS S3 (Simple Storage Service) is used to store the processed documents.
Reasons for choosing S3 and Textract:
S3 is a highly scalable, durable, and secure object storage service. It is an ideal choice for storing large documents due to its unlimited storage capacity, high availability, and low latency.
S3 provides features like versioning, lifecycle management, and encryption, which are essential for managing sensitive documents securely.
Textract is a powerful OCR (Optical Character Recognition) service that automatically extracts text, handwriting, and data from scanned documents. It eliminates manual data entry and speeds up the document processing workflow.
Textract's ability to extract unique identifying numbers from documents enables efficient search and retrieval of specific documents from the portal.
Using S3 for storage and Textract for data extraction, we modernized the document management process, significantly improving efficiency and user experience.
If you’ve made it this, we actually go through architectures and real-world examples and build hands-on projects like the document storing solution in my academy. You can have discounted access to my Cloud Engineer Academy by using coupon code LAUNCH100 :)
Speak soon,
Soleyman
wouldn't it also be useful to add Macie to scan the architecture to assure security on PII in the companies S3 buckets?